
From Playground to Database: child data in education
In England’s schools, children are tracked from birth through a vast, opaque network of digital systems that turn education into a lifelong exercise in data collection and surveillance.
Long Read
Post date
28th October 2025
In England’s schools, children are not only pupils but also data subjects. From the moment they are born, a digital record begins to take shape — one that will follow them through nursery, primary school, secondary education, and in many cases well into adulthood.
What was once a matter of paper registers and filing cabinets has become a complex infrastructure of digital systems, databases, and analytics tools, managed by both the state and private companies, for AI, surveillance, and more.
Education has always required some record-keeping, but the scale and permanence of today’s systems are new. A child’s background, behaviour, health, and even predicted future performance are logged, shared, and sometimes resold. This information flows through networks of schools, local authorities, social services, and commercial vendors, often invisibly to the families involved.
For children, the act of simply showing up to school now generates streams of data that may shape how they are understood, treated, and categorised by institutions.
What data?
Children’s data in education starts from the day they are born up until they are 25 years old.
It begins during pre-school, with personal data submitted by legal guardians during the school admissions process (typically nursery is from age 0-5, or statutory school age 5).
This is required by the school for administrative purposes, with the child assigned a unique pupil record and unique pupil number (“UPN”) that stays with them forever.
The student’s educational setting gets added to the record, which includes its religious character and location. Attainment data (age 2-5) in the Early Years Foundation Stage profile is added, and will be joined later by all other statutory tests and examinations a child’s takes until they are 18.
Some data, such as a child’s ethnicity, is infamously inaccurate. When a parent has not provided a child’s ethnicity, some schools were told they could “ascribe” or guess it.
The next layer of data added to those records is created by school staff - absence and attendance records, assessment, and attainment data showing statutory test scores, or individual behaviour records and sensitive data about injuries or harm from safeguarding concerns.
While this data was once only local administrative data, locked in storage cupboards on a school site, they are increasingly now stored in cloud-based third-party commercial systems, and go on to become the repository and source of statutory collections submitted to the national Department for Education.
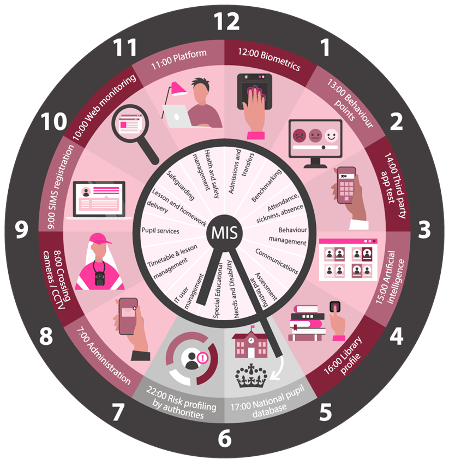
Source: Defend Digital Me report, the State of Data (2020)
In UK state schools, at the centre of the data collection (and sharing) arrangements is the school Management Information System or MIS - as shown in the diagram above.
A MIS (also referred to as the School Information Management System or SIMS) routinely brings together pupil, family and staff data, including sensitive data with fixed characteristics, such as ethnicity. It also contains changing characteristics: home address, health, records of incidents at points in time, such as safeguarding records.
Some of these school information management systems are starting to integrate AI functionalities into their products from search, to chatbots, to student feedback responses.
Schools may add in further information from multiple outside sources beyond the school, including Local Authority information, police data, or children’s social care.
Many of those data can be further shared with other state authorities at local and regional levels, so there is a flow from and to other agencies connected to the educational institutions via the Internet.
Separately, children’s data can be generated and collected by the EdTech tools they use while in education. This data is largely analytics, about how often a tool is used and how long, but can also include the length of time taken to answer a question - with the student then benchmarked against other system users anywhere in the school or even in all of the users across the country.
Some schools use a broad range of tools, such as behaviour tracking apps - which can take the form of scores but also of more complex profiles and predictions in relation to a child.
In the transition to each stage of education, further personal data are collected and added to the National Pupil Database (NPD), containing personal data including, special needs status, free school meal eligibility, and more. Since the national records began to be collected on a named basis in 2002, they have been kept indefinitely.
As a student enters higher education, the Higher Education Statistics Agency (HESA), starts collecting data on their gender identity, sexual orientation, and religious beliefs.
In summary: data is provided by parents and guardians about the child to the school, data is created by teachers about the child in the school, and data is created by the child while outside the school.
This is data that the children see and do not see — entered knowingly and collected unknowingly from data usage and analytics.

Accessed by whom?
Who can access and use pupil data has also grown in scope and scale. Schools distribute and collect pupil data from public authorities and private companies.
Public authorities includes a wide range of state and quasi-state entities: local authorities, welfare agencies, police, and community health services. They routinely access pupil information from school records as the primary data source about children in their area.
In Bristol, for example, the ‘Think Family Education’ app is used by over 100 schools - sending ‘crime incidents’, including police reports about school children, to school safeguarding leads.
Schools also get access to ‘predictive’ alerts from the police about children that might be at risk of criminality, as well as antisocial behaviour and domestic violence incidents and personal details about their finances.
This is based on data collected from approximately 50,000 families in Bristol by the organisation Insight Bristol, comprised of staff from Avon and Somerset Police and Bristol City Council.
These other entities may also see, and share yet further, any analyses of pre-school or in-school assessment data and the resulting profiles, scores or predictions obtained from the MIS.
In Kent, a Children’s and Young People’s Integrated Database was built by linking Phonics, SATs, and Key Stage results from schools across the county.
It also includes ‘Mosaic’ data, which can include financial data, property records, and lifestyle data, from consumer data broker Experian. This data can be shared with health and housing services, medical professionals, and the police.
Core pupil data from school MIS are also transferred out of the educational setting for every pupil on roll to be retained in the national databases, for example by the UK Department for Education through the termly or annual school census. Together they build up the longitudinal pupil record throughout an individual’s education until typically around age 25 for children with special educational needs (SEND), or for those who proceed to Higher Education.
From there, the Department for Education sends data to third-party, private companies - who then might resell the data back to schools after processing it to profile their pupils. The profiles may include risk scores of achieving or not achieving expected progress — the company’s prediction of future academic performance, weighted for summer-born children and other factors profiled against other ‘similar pupils’ — and the schools can then buy these processed data back and some use them to target interventions with key children whose outcomes may affect school progress measures.
Organisations such as the Administrative Data Research UK (ADRUK), a government-funded program to make better use of administrative data, claims that data linking and sharing provides a holistic view of students’ academic journey - one that will improve outcomes for children.
However, mixing data collected in different contexts for different purposes is ‘high risk’ according to the ICO, and using tools built on artificial intelligence software to create scores or profiles risks flawed conclusions based on a lack of data, incorrectly analysed data, or bias.
AI in education also has dire implications. AI can be inaccurate, biased, and so the scores, profiles, and predictions created by it may not be suitable.
Inappropriate application of AI in education may have dire implications, from the creation of false inferences to resulting damaging interventions. AI can be inaccurate and biased, and so the scores, profiles, and predictions created by it may be wrong but hard for teachers to see. The data the AI is working with, have often been created for a totally different purpose, and are unsuitable to be used for something else. Primary school SATs scores for example, used as indicators of anything individual about a child beyond their design as institutional progress measures.
Despite governments’ accelerating how AI is implemented into their services, regulators are only just beginning to recognise the issues and legislate on them, such as the EU AI Act and the Council of Europe’s AI Framework Convention.
Some areas of activity are banned entirely in the education sector, but others are made permissible as long as their high-risk impact is assessed and justified. But the EU AI Act application is limited by geography. Countries outside of the EU, such as the UK, may not even have any regulation in this area at all.
The story of children’s data in education is not only about questions of efficiency or accountability. It is also about trust, power, and control.
Data protection law is generally permissive and rarely protects children’s privacy in educational settings.
Digital pupil records and EdTech have enabled the dissolving of the boundary between home and school, records no longer stay inside the school building, accessible only within the hours of the school day or kept and shared only until a child leaves education.
Every database entry, predicted score, and profile built from behaviour or background can influence a child’s life far. For some children it may open doors; for others it may close them.
Schools are no longer asking whether data should be collected, and rarely pay attention to how to minimise it. So we must ask what they are collecting, why, and what boundaries are to be drawn around its use.
Are schools to remain places of learning, or are they becoming laboratories of surveillance, where childhood itself is quantified and commodified?
Until those questions are answered, children will continue to grow up inside systems they cannot see, feeding algorithms they cannot understand, and ranked by judges they cannot contest.
This series is possible thanks to the work of Defend Digital Me and Douwe Korff.
Our campaign
Learn more
Glossary
