Guide to using an AI chatbot that runs locally (and doesn’t share your data)
This guide explains how to run Jan, a local AI chatbot that can run offline to have complete control over your data.
AI chatbots are used by people in a variety of ways, including to conduct research, create content and analyses, deliver projects, and engage in conversations. We are concerned these AI tools can pose privacy and security risks when offered by tech firms, as they give these companies greater access to your data and access to our personal and professional lives.
As these AI firms start to figure out their business models, they're likely to resort to the same data exploitation methods that served industry so well under surveillance capitalism. Also, similar to how search companies must share data with law enforcement when required to, so can AI chatbot providers be called upon to share your chat history.
One way to limit risks like these is to run an AI chatbot directly on your device. In this scenario, instead of sending your prompts to a company's servers over the internet, everything happens on your machine. While doing this requires a device that is relatively powerful (as it needs to be able to do all the processing required to run the AI chatbot), and the performance might not be as good as commercial alternatives, there are still strong privacy benefits. Additionally, this means you can use it offline.
If you are going to run your own chatbot on your device, this guide covers:
- How to install an application that runs LLMs
- How to download and run an LLM
- Extend LLMs capabilities with MCP
- Advanced tweaks to improve performance
Before you start
Running an LLM is computationally demanding. It requires a large amount of processing power, a decent amount of RAM, and storage to store the models. With a recent enough CPU, 16GB of RAM (minimum) and 50GB of available disk space, you should be able to run small models. But having a dedicated graphics card (GPU), ideally with a decent amount of VRAM, will significantly improve performance.
Install an application that runs LLMs
Running an AI chatbot consists of two moving parts: the Large Language Model (LLM) which is the “brain” of the chatbot, and an application capable of running it and delivering its outputs.
There are many applications that can run LLMs locally on your desktop while presenting an interface similar to popular AI chatbots like ChatGPT. Different applications will offer different capabilities such as image generation, Model Context Protocol (MCP) or the ability to handle code artefacts (similar to ChatGPT canvas). Check the list of features to make sure the tool you want to use matches your expectations.
In this guide, we will use Jan as it’s open source, is available for various operating systems (Linux, MacOS, and Windows), supports plugins, and has a vibrant community behind it. You might also consider using LM-Studio, a popular alternative that is not open source but offers similar features. For more complex alternatives, you can try LibreChat, a very complete open-source project, or Open-WebUI, but they require more technical knowledge to setup.
To install Jan, visit https://jan.ai/ and download the appropriate installer for your system. Alternatively, you can find the installer on Jan’s GitHub repository. Follow the instructions and launch Jan once the install process is finished.
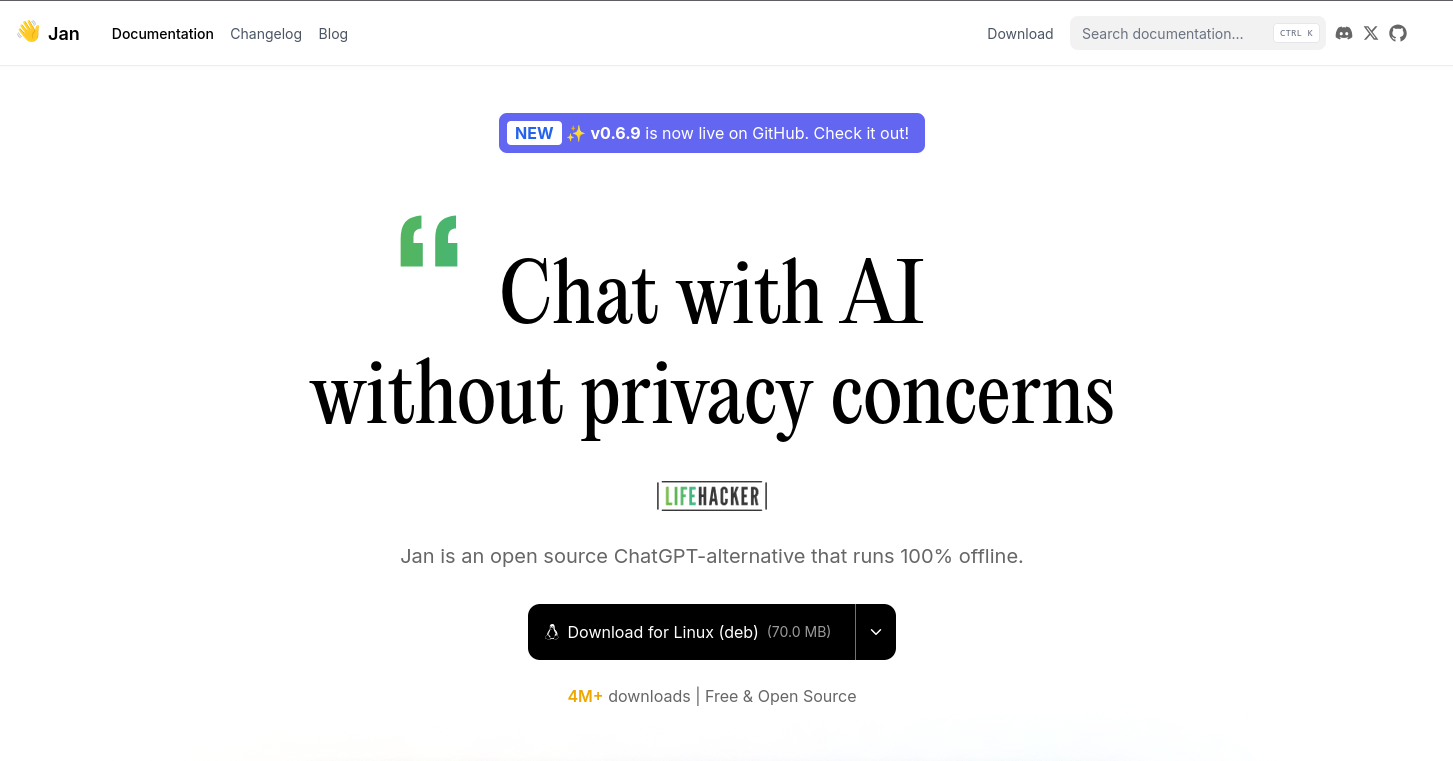
If you have a dedicated GPU, check that it’s successfully detected and used. You can do so by clicking Settings at the bottom of the menu on the left, navigate to Hardware and checking that your GPU is enabled.
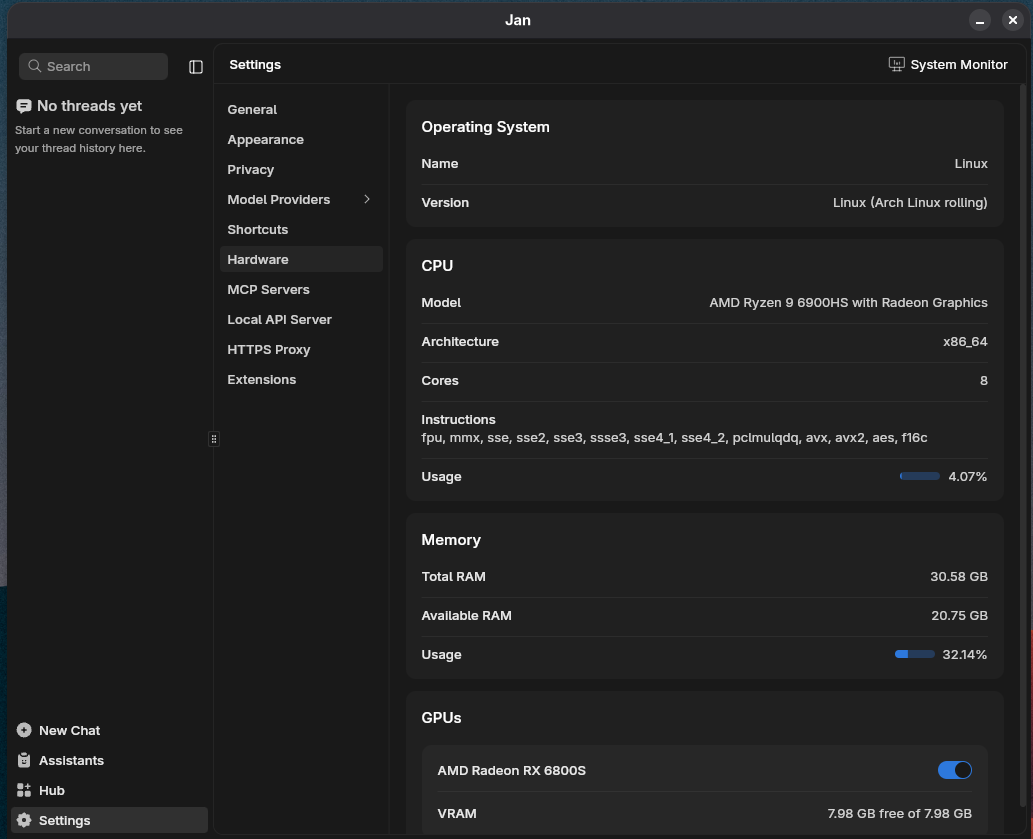
Download and run an LLM
Different models will offer different capabilities. Gemma 3 by Google and Mistral Small 3.2 for example can process images, something OpenAI’s gpt-oss can’t do. Qwen3 has “reasoning” capabilities, which basically means it is able to show you step by step how it got to an answer.
Before downloading a model, you should consider a few things:
- What are the models’ capabilities and do they fit your needs?
- How large is the model and how much space does it take on your computer?
- What languages does it support (related to what languages it was trained on)?
- How recent is the model (models are improved at a quick pace and recent models can be much more powerful)?
Model names usually include the number of parameters within the model, which is a good way to identify how big the model is, and how demanding it will be in terms of processing power. For example:
- gemma-3-4b: has 4 billions parameters, which makes it easier to run on most machines.
- qwen3-30b: has 30 billions parameters and will require a more powerful computer.
The sizes of the models available also vary a lot, for example gemma-3-4b is 2.37GB while qwen3-30b is 17.5GB.
Finally, some models will mention Q with a number ranging from 1 to 8 in their name, referring to the level of quantization. LLM quantization is like compressing a very large, detailed image into a smaller, less detailed version to make it easier to store and view. If in doubt just start with the Q4 version of the model if you have the choice. The higher this number is, the less compression is done and the more powerful your computer needs to be. Feel free to experiment with Q6 and Q8 if you have a dedicated GPU.
Jan allows you to download models directly from its interface and will tell you if your computer is powerful enough to run it. To do so, click on Hub in the bottom left corner. From there, you can either browse the recommended models or search for something specific.
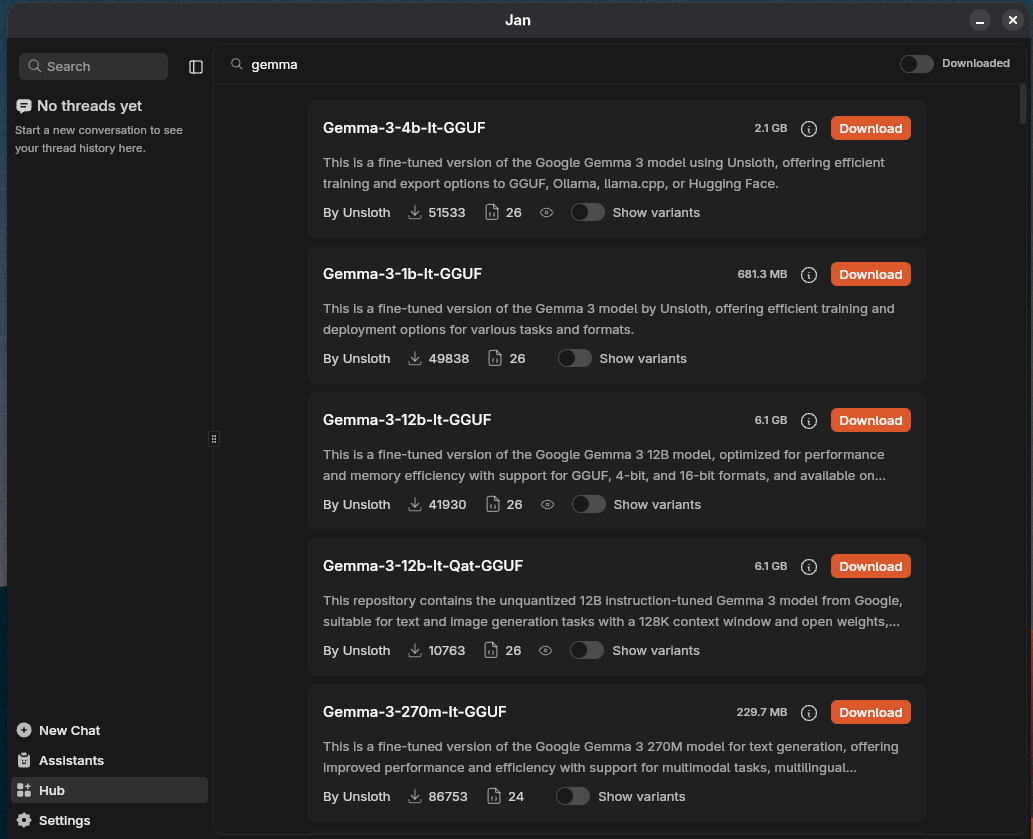
Hovering on the info icon next to the model size will give you information about whether the model will likely perform well on your machine or not.
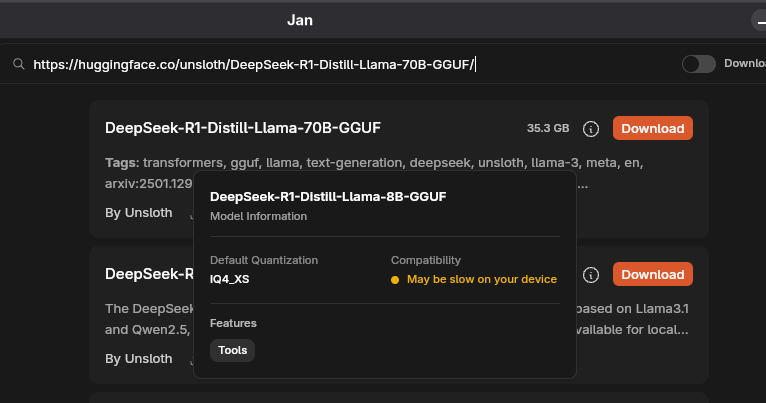
You can also search models via a HuggingFace URL. Finally, you can import any model in GGUF format directly by going to, for instance, Settings > Model Providers > Llama.cpp and clicking Import.
A note on using commercial services (remote providers): You might notice in Settings > Model providers that Jan allows you to connect to remote AI providers like openAI, Anthropic, Groq, Google and Mistral using an API key. Doing this means the processing will be done on these companies’ servers and your chats will be shared with them, essentially cancelling most of the privacy and security benefits of using software to run local LLMs.
Once you have downloaded a model, click on New chat in the left-hand menu, select your model and start chatting.
Found a mistake? An outdated screenshot? Think this could be improved? Check out our Github repository and contribute to help keep these guides up-to-date and useful!


